机器学习算法的性能评估
机器学习算法的性能评估¶
为什么需要评估机器学习算法的性能¶
当我们辛苦开发出来的机器学习算法不能很好地预测新数据时,我们该怎么办呢?一般情况下,有以下几个方法:
- 获取更多的训练数据
- 减少输入的特征数量,避免出现过拟合
- 增加有价值的特征,即重新解读并理解训练数据
- 增加多项式特征
- 减小正则化参数 $\lambda$
- 增大正则化参数 $\lambda$
如何评估机器学习算法,以便遇到问题时能知道用上面方法中的哪个方法?
- 对机器学习算法的性能进行评估,接下来就要介绍机器学习算法性能评估的方法
- 对机器学习算法进行诊断,诊断是指通过对机器学习算法进行测试,以便找出算法在哪种情况下能良好地工作,哪种情况下无法良好地工作。进而找出算法性能优化的方向和方法。
预测函数模型性能评估¶
怎么样判断我们的预测函数模型的性能是可以接受的呢?
我们可以把训练数据集分成两部分,随机选择 70% 的训练数据作为训练数据集,用来训练机器学习算法;另外 30% 作为测试数据集,用来验证训练出来的机器学习算法针对这些测试数据集的误差。一个好的机器学习算法应该是对训练数据集成本比较低,即较准确地拟合数据,同时对测试数据集误差比较小,即对未知数据有良好的预测性。
如何计算测试数据集的误差呢?
简单地说,就是用测试数据集和训练出来的机器学习算法参数,代入相应的成本函数里计算测试数据集的成本。
针对线性回归算法,我们可以使用下面的公式计算测试数据集的误差,其中 m 是测试数据集的个数:
$$ J_{test}(\theta) = \frac{1}{2m} \sum_{i=0}^m \left( h_\theta(x^{(i)}) - y^{(i)} \right)^2 $$
针对逻辑回归算法,可以使用下面的公式计算测试数据集的误差,其中 m 是测试数据集的个数:
$$ J_{test}(\theta) = -\frac{1}{m} \sum_{i=1}^m \left[ log(h_\theta(x^{(i)})) + (1 - y^{(i)}) log(1 - h_\theta(x^{(i)})) \right] $$
针对分类问题时,还可以用分类错误率来代替成本函数算法,从而更直观地观察到一个算法对测试数据集的误差情况。我们定义错误率为:
$$ err(h_\theta(x), y) = \begin{cases} 1, & \text{if error classification. $h_\theta(x) \geq 0.5$, $y$ = 0 or $h_\theta(x) < 0.5$, $y$ = 1} \\ 0, & \text{if correct classification. $h_\theta(x) \geq 0.5$, $y$ = 1 or $h_\theta(x) < 0.5$, $y$ = 0} \\ \end{cases} $$
如何直观地理解错误率?如果预测出错了 (即实际值是 1 预测为 0 ,或者实际值是 0 预测为 1) ,则成本算为 1 。如果预测正确了,成本算为 0 。
测试数据集的错误率定义为:
$$ Test Error = \frac{1}{m} \sum_{i=0}^m err(h_\theta(x^{(i)}), y^{(i)}) $$
其中,m 为测试数据集的个数,$(x^{(i)}), y^{(i)})$ 为测试数据。直观地理解,就是针对测试数据集,其错误预测的数据的个数。
模型选择¶
模型选择问题包括怎么样选择多项式来拟合数据,怎么样把数据集分成训练数据集,验证数据集,测试数据集,怎么样确定正则化参数 lambda 的值等等。
以多项式模型选择为例。假设我们用一阶多项式,二阶多项式,三阶多项式 … 十阶多项式来拟合数据,多项式的阶数我们记为 d。我们把数据集分成训练数据集和测试数据集。先用训练数据集训练出机器学习算法的参数 $\theta^{(1)}, \theta^{(2)}, \theta^{(3)}, … , \theta^{(10)}$ 分别代表从一阶到十阶多项式的参数。这个时候我们再用测试数据集算出针对测试数据集的成本 $J_test(\theta)$ 看哪个模型的测试数据集成本最低,这样我们选择这个测试数据集最低的多项式来拟合我们的数据。但实际上,这是不公平的,因为我们通过测试数据集的成本来选择多项式时,我们可能选择了一个针对测试数据集成本最低的多项式,即在模型选择过程中,我们通过测试数据集拟合了多项式的项数 d。
为了解决这个问题,我们把数据分成三部分,随机选择 60% 的数据作为训练数据集,其成本记为 $J(\theta)$,随机选择剩下的 20% 数据作为交叉验证数据集 (Cross Validation),其成本记为 $J_{cv}(\theta)$,剩下的 20% 作为测试数据集,其成本记为 $J_{test}(\theta)$。
在模型选择时,我们使用训练数据集来训练算法参数,用交叉验证数据集来验证参数,选择交叉验证数据集的成本 $J_{cv}(\theta)$ 最小的参数来选择合适的模型多项式 d ,最后再用测试数据集来测试选择出来的模型的针对测试数据集的错误率。因为在模型选择过程中,我们使用了交叉验证数据集,所以适配模型多项式 d 的过程中,实际上是没有使用我们的测试数据集的。这样保证了使用测试数据集来计算成本时,确保我们选择出来的模型没有见过测试数据,即测试数据集没有参与模型选择的过程。这样算出来的针对测试数据集的成本是相对公平合理的。
当然,在实践过程中,很多人直接把数据集分成训练数据集和测试数据集,然后通过比较测试数据集选择的成本来选择模型。
方差与偏差 Bias vs. Variance¶
假定 $J_{train}(\theta)$ 表示训练误差;$J_{cv}(\theta)$ 表示交叉验证误差;那么高方差意味着 $J_{train}(\theta)$ 很大,$J_{cv}(\theta)$ 也很大,这时算法是欠拟合的。高偏差定义为 $J_{train}(\theta)$ 很小,但 $J_{cv}(\theta)$ 很大,这时算法是过拟合的。
正则化与方差及偏差的关系¶
当 lambda 为零时,容易产生过拟合,即 $J_{train}(\theta)$ 很小,但 $J_{cv}(\theta)$ 很大,这个就是高偏差的定义。而当 lambda 太大时,$J_{train}(\theta)$ 很大,$J_{cv}(\theta)$ 也很大,此时会产生高方差。
可以把数据集的成本作为纵坐标,lambda 作为横坐标,把 $J_{train}(\theta)$ 和 $J_{cv}(\theta)$ 以及 lambda 画在一个二维坐标轴上,这样我们可以明显地看到 $J_{train}(\theta)$ 和 $J_{cv}(\theta)$ 随着 lambda 的变化规则,从而编程自动找出最合适的 lambda 值。
学习曲线¶
我们可以把 $J_{train}(\theta)$ 和 $J_{cv}(\theta)$ 作为纵坐标,画出与训练数据集 m 的大小的关系。
我们可以观察到当高偏差 (High Bias, Under Fitting) 时,随着训练数据集的增加,$J_{cv}(\theta)$ 不会明显地下降,且 $J_{train}(\theta)$ 增加很快,且最终$J_{train}(\theta)$ 和 $J_{cv}(\theta)$ 的值非常接近,且两个值都比较大。这个就是过拟合的表现。从这个关系也可以看出来,当发生高偏差时,过多的训练数据样例不会对算法性能有较大的改善。
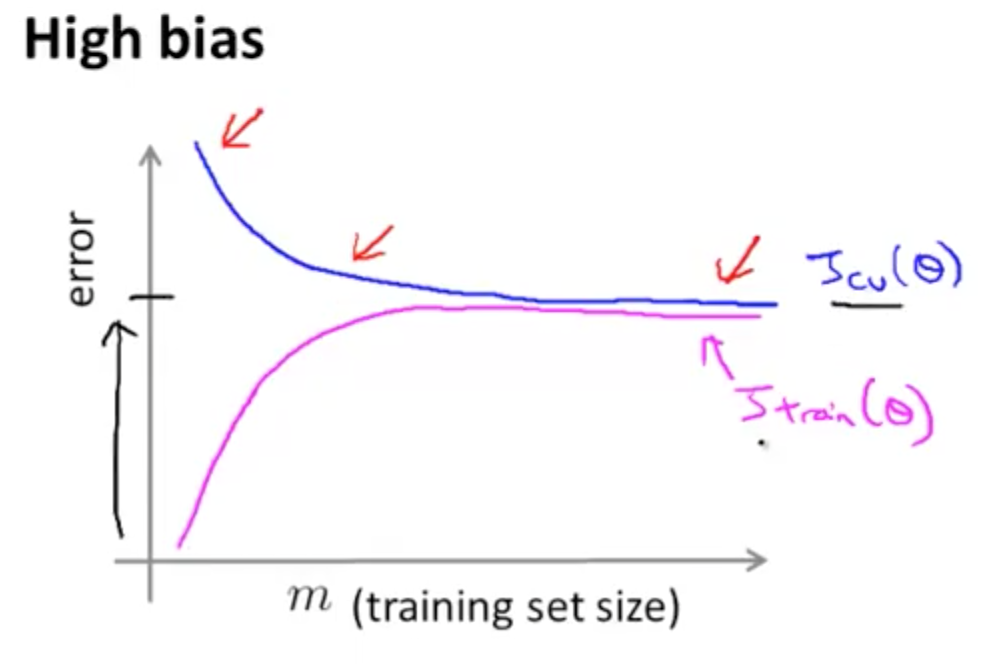
当高方差产生时 (High Variance, Over Fitting),比如我们用 100 阶的多项式来拟合数据。随着训练数据集 m 的增加,$J_{train}(\theta)$ 的增加比较缓慢,且值比较小。而 $J_{train}(\theta)$ 刚开始时很大,随着训练数据集 m 的增加,它会开始缓慢下降,但其值还是比较大。最终 $J_{train}(\theta)$ 和 $J_{cv}(\theta)$ 的值相差比较大。当发生高方差时,更多的训练数据样例会对算法性能有较大的改善,因为最终两条线会越来越接近,达到我们想要的效果**。
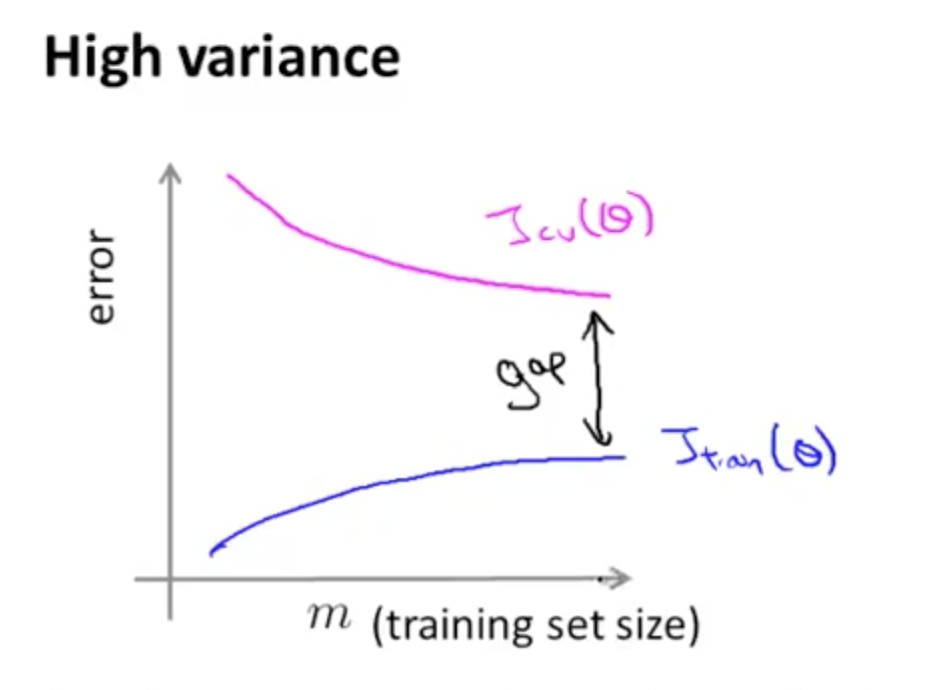
当需要改进学习算法时,可以画出学习曲线,以便判断算法是处在高偏差还是高方差问题。
决定下一步行动¶
回到本周开始的地方,我们可以总结那些行动可以解决哪些算法问题。
- 获取更多的训练数据 -> 解决高方差问题 (High Variance, Over Fitting)
- 减少输入的特征数量,避免出现过拟合 -> 解决高方差问题
- 增加有价值的特征,即重新解读并理解训练数据 -> 解决高偏差问题 (High Bias, Under Fitting)
- 增加多项式特征 -> 解决高偏差问题 (High Bias, Under Fitting)
- 减小正则化参数 lambda -> 解决高偏差问题 (High Bias, Under Fitting)
- 增大正则化参数 lambda -> 解决高方偏差问题 (High Variance, Over Fitting)
神经网络的过拟合¶
针对神经网络时,我们可以设计两套方案。第一套方案是使用小型的神经网络,即只有一个隐藏层,隐藏层的神经单元个数也比较少。第二套是使用大型的神经网络,可以有多个隐藏层,每个隐藏层有多个神经单元。
一般来讲,方案一可能会导致高偏差,即欠拟合,但计算成本很低。而方案二可能会导致过拟合,且计算成本很高。针对欠拟合的情况,我们可以通过调整正则项参数 lambda 来解决。一般来讲,针对一个实际问题,选择一个大一点的神经网络,通过 lambda 纠正过拟合现象,这样的神经网络架构会比小型神经网络性能要好。
另外一个问题,多个隐藏层好还是一个隐藏层好呢?针对不同的实际问题结论是不一样的。一个通用的方法是在不同隐藏层个数的神经网络里进行比较,通过计算交叉验证数据集的成本 $J_{cv}(\theta)$ 来判断哪个网络更适合我们的实际问题。